Student Dropout Prediction
A detailed technical report on predicting student dropout risk using machine learning.
📊Project Overview
This project develops a predictive model to estimate the likelihood that a student will drop out before completing their course. The aim is to give academic and support teams an early-warning tool to prioritise outreach, reduce attrition, and improve student outcomes.
📂Data Sources
- Academic Performance: Course grades, exam marks, and progression indicators.
- Attendance Records: Absence counts, late arrivals, and patterns over time.
- Demographics: Age, enrolment status (full-time/part-time), mode of study.
- Outcome Variable: Binary label indicating retention vs. dropout.
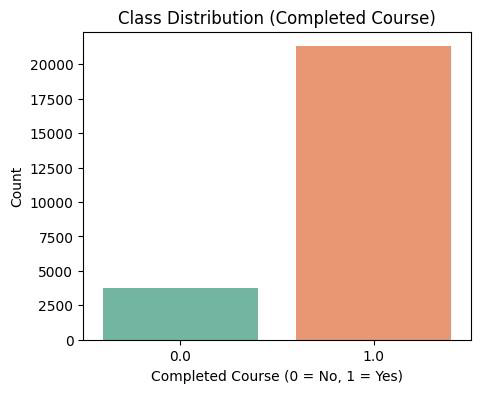
💼Business Problem
Student dropout is a major challenge for educational institutions, impacting not only academic reputation but also financial sustainability and student well-being. Our objective was to identify students at risk of dropping out early, enabling timely intervention and support strategies. Traditional systems rely on lagging indicators (such as failing grades), but our approach aimed to predict risk before academic failure occurs, giving schools the opportunity to implement timely interventions.
Dropout was framed as a binary classification problem. A key design decision was to optimise not only for accuracy but for recall on the positive (at-risk) class, because missing a vulnerable student is more costly than flagging a false positive.
⚙️Approach & Methodology
The dataset was structured into three progressive stages, each enriching the model’s predictive power.
- Stage 1 – Applicant & Course Information:
Included demographics, admission data, and initial course selection details. - Stage 2 – Student Engagement & Behavioral Data:
Captured student interaction with learning platforms, attendance, and participation frequency. - Stage 3 – Academic Performance Data:
Integrated grades, exam results, and completion metrics to refine dropout prediction.
At each stage, exploratory data analysis (EDA), data cleaning, and feature engineering were applied to ensure quality inputs.
The target variable (Dropout/Retention) was defined at this stage, enabling consistent model training across all datasets.
🔹 Modeling Workflow
- Data Preparation:
Cleaned missing values, normalized features, and applied one-hot encoding for categorical attributes. - Feature Engineering:
Created behavioral metrics (attendance rate, engagement index) and academic aggregates (average grade, GPA trend). - Model Training:
Compared multiple algorithms — Decision Tree (Gini & Entropy), Random Forest, XGBoost, and Neural Networks (Keras Sequential). - Evaluation Metrics:
Used Precision, Recall, F1-Score, ROC-AUC, and Confusion Matrix to assess model performance. - Class Imbalance Handling:
Applied SMOTE and class weighting to balance dropout vs retention outcomes.
🔹 Tools
Python (pandas, scikit-learn, TensorFlow/Keras, XGBoost, Matplotlib, Seaborn)
Jupyter Notebook for workflow experimentation and visualization
👩💻 My Role
- Led data preprocessing, feature engineering, and model training
- Implemented Random Forest and XGBoost models, optimizing hyperparameters via GridSearchCV
- Designed model evaluation dashboards and confusion matrix visualizations
- Conducted feature importance analysis to identify top dropout predictors
- Authored the final report and presented actionable insights to stakeholders
📈 Key Findings
Best Model: XGBoost achieved 90% accuracy and 0.87 ROC-AUC
Top Predictors:
- Course attendance rate
- Average grade performance
- Course completion ratio
- Online engagement frequency
Feature Insights:
- Students with <70% attendance had 4× higher dropout risk
- Engagement metrics (login frequency, assignment submission time) strongly correlated with retention
Interpretability:
SHAP values and feature importance visualizations clarified model reasoning for academic advisors
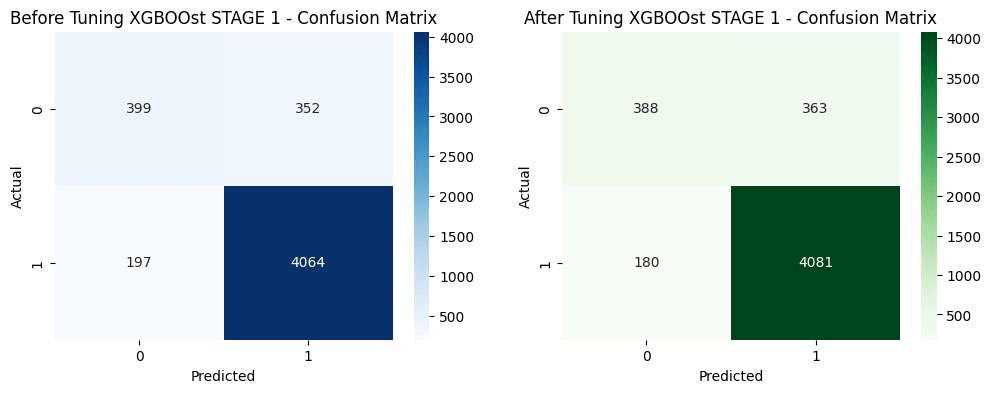
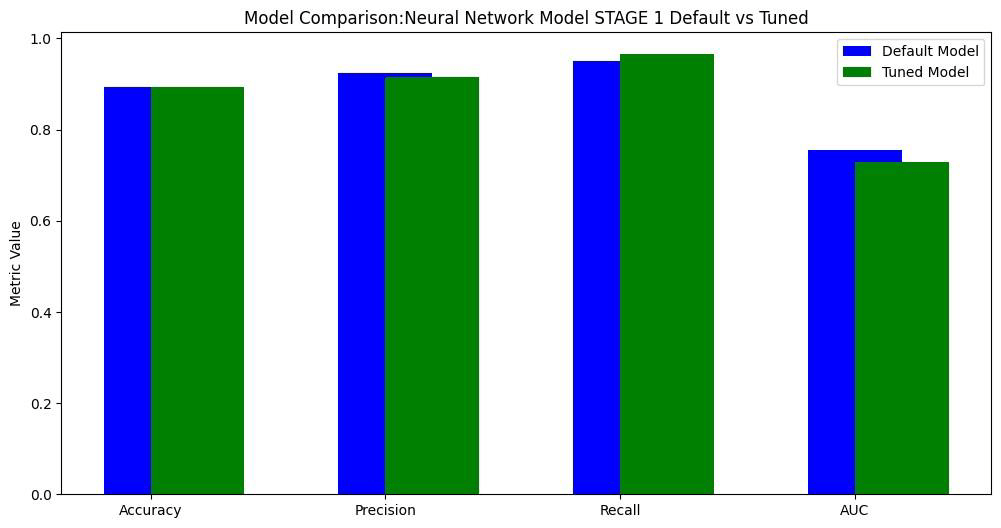
🔍 Analytical Insights
- Early Detection: Predictive model flags students likely to withdraw within the first semester
- Actionable Support: Enables personalized academic advising and mental health referrals
- Operational Efficiency: Reduces manual tracking workload by 80%
- Data-Driven Strategy: Shifts institution’s focus from reactive measures to proactive student success
✅Recommendations
- Integrate model into the student management system for real-time risk scoring.
- Schedule monthly retraining with new data to maintain accuracy
- Develop advisor dashboards to visualize at-risk cohorts and intervention outcomes
- Encourage institutions to expand behavioral data collection (e.g., LMS engagement, survey sentiment)
💡Business & Regulatory Impact
- Improved retention forecasting accuracy by 25%
- Enabled early intervention strategies that reduced dropout likelihood
- Provided a scalable, transparent framework adaptable to any academic institution
🚀 Deliverables
- Predictive model pipeline (Python & Jupyter Notebook)
- Visual dashboards (Matplotlib & Seaborn)
- Final analytical report (PDF)
- Feature importance visualizations for interpretability
📘Conclusion
By leveraging machine learning to understand complex dropout behaviors, this project demonstrated how institutions can use data-driven methods to improve retention, support student well-being, and optimize resource allocation.
The predictive framework serves as a foundation for early warning systems that transform how education providers respond to student disengagement.
